Will AI Replace Software Developers?Заменит ли ИИ разработчиков?Wird KI Softwareentwickler ersetzen?L'IA va-t-elle remplacer les développeurs ?AI 会取代软件开发者吗?
Lately, the question “Will AI replace us?” has worried many people. We can see how LLMs handle programming tasks very well and write code at a middle to senior level. This makes many software developers concerned about their future.
Introduction
To be honest, I rewrote this article several times and spent more time on it than usual. I didn’t want to take the side of people who are against AI, that’s not how I see it. I’ve been using LLMs in my daily work for several years, and it’s hard to imagine working without them. Not because I wouldn’t be able to code or solve complex problems, but because my efficiency would definitely be lower.
AI is evolving faster than most developers can adapt, and we’re seeing major changes in the IT industry. Because of that, many people feel stress, denial, or even hostility toward AI. But most of these feelings are driven not by real threats, but by hype and strong marketing from large AI providers.
The goal of this article is not to show that AI is weak or useless, or that we shouldn’t use it. Not at all. I want to highlight the other side, the one that people don’t talk about enough. LLMs are powerful tools, but they come with limitations and require skilled professionals who understand what they are doing.
Artificial Intelligence in Software Development
Modern LLMs have truly become powerful tools for software development. Claude Code or Codex can write high-quality, well-structured, and quite complex code. It can work with large codebases and understand the project context.
To understand whether AI can replace software engineers in the future, let’s first look at the main question: does an LLM really understand why this code is needed?
As you know, an LLM works by predicting the most likely continuation of a sequence of tokens based on a huge amount of training data. In simple words, modern AI does not “think” and does not “understand” the goal of the system. It statistically decides what is most logical to write next.
That is why LLMs show excellent results in typical and well-defined tasks:
CRUD applications, standard REST APIs, simple SPAs built with Angular or React, and template-based business logic. All of this appeared many times in the training data, so the model can confidently reproduce familiar patterns.
Problems begin when deep understanding of the domain and execution context is required. For example, when designing a distributed system with complex requirements for fault tolerance, data consistency, and business constraints. In such tasks, AI may generate code that looks “clean” and correct, but:
does not consider real load scenarios,
breaks important business logic rules,
or suggests architectural solutions that cannot work in the given environment.
The more complex the system, the wider the context, and the less formal the request, the higher the chance that the model will get confused, hallucinate, or move toward wrong solutions.
Why Scaling LLMs Is Not Enough
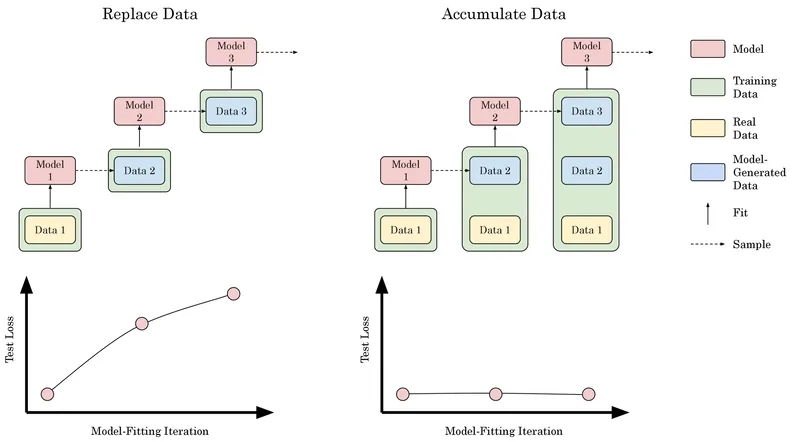
One of the biggest challenges in building more powerful LLMs is the quality of the data they are trained on. Even if we keep scaling models, issues like model collapse can limit progress. When models are trained on data that already contains AI-generated or low-quality content, they can start amplifying errors, repeating mistakes, or learning unrealistic patterns. Simply making models bigger won’t solve the underlying problem, the foundation itself needs to be clean and reliable.
Yann LeCun, a Turing Award winner and one of the founders of modern AI, and former Chief AI Scientist at Meta, believes that simply increasing the size and power of LLMs will not help. According to him, this is not the path to real artificial general intelligence (AGI).
He argues that real intelligence needs a model of the real world, including physics, cause and effect, and goals. Language alone is not enough:
“We need systems that understand the physical world, not just systems that generate plausible text.”
Programming requires planning, reasoning, and understanding long-term consequences. LLMs can help write code, but they do not truly design systems or understand why solutions work. That is why, no matter how powerful new models become, the same fundamental problem remains.
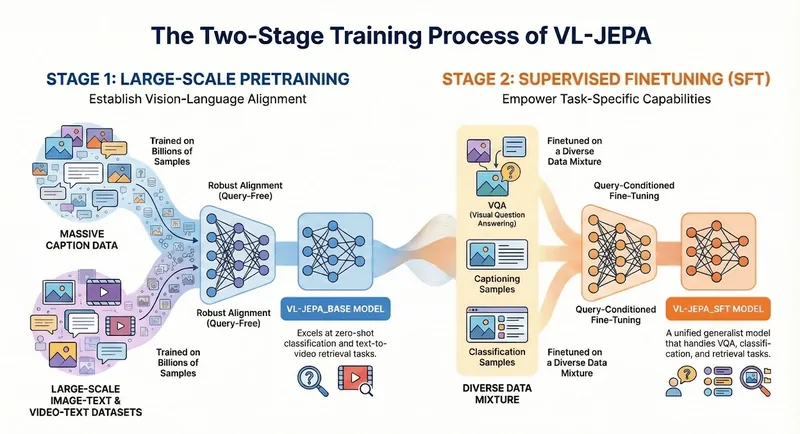
At the same time, Yann LeCun is working on a new AI architecture called VL-JEPA (Vision-Language Joint Embedding Predictive Architecture). This is not a classic generative approach like GPT models. Instead of predicting text token by token, the model works at the level of semantic representations. It does not generate answers word by word. It predicts a semantic representation of the answer, a kind of “meaning fingerprint.” If needed, this representation can later be decoded into text.
VL-JEPA may be more efficient than traditional multimodal models because it does not spend computation on generating every token. In tasks such as classification, video understanding, video search, and visual question answering, this approach can be lighter and faster. The architecture is also more universal: the same model can solve classification, search, and question-answering tasks without training a separate model for each one.
The Worst Trend of 2025 – Vibe Coding
The term “vibe-coding” appeared in February 2025, when the co-founder of OpenAI mentioned it on X (Twitter). He wrote that it is a great way to create code using natural language and full trust in AI, instead of traditional manual coding. After that, there was a huge wave of hype. And why not? Now you can just talk to AI, and it will do what people studied for at university and practiced for years.
The marketing was very strong. Many people outside of IT started building their own web services. Some even fired programmers, why pay more if you can buy a $20 subscription and do everything yourself? After some time, we began to see the results: API keys committed to public repositories, security vulnerabilities in websites, and cases where people spent $300–400 in one evening because too many tokens were used. In some cases, the whole application simply stopped working.
If you think this only happens to naive beginners in the profession, let’s take a deeper look at this topic.
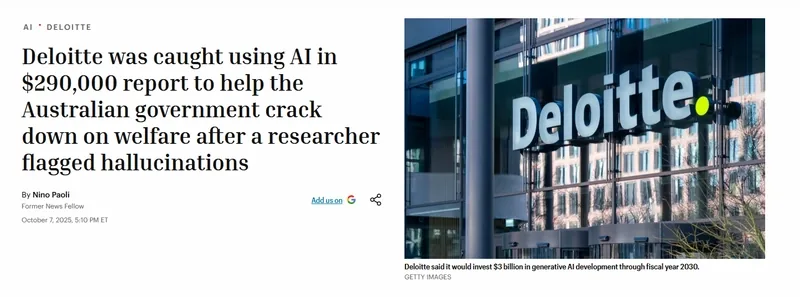
You may have heard the news that in the summer of 2025, Deloitte was involved in a scandal. It turned out that their report for the government of Australia was partially generated by ChatGPT and included non-existing laws and references to false facts. I would call this “vibe-lawyer.” The company faced both financial and reputational losses. And this is a global-level company. In such companies, reports go through many departments and people. But we can see the result.
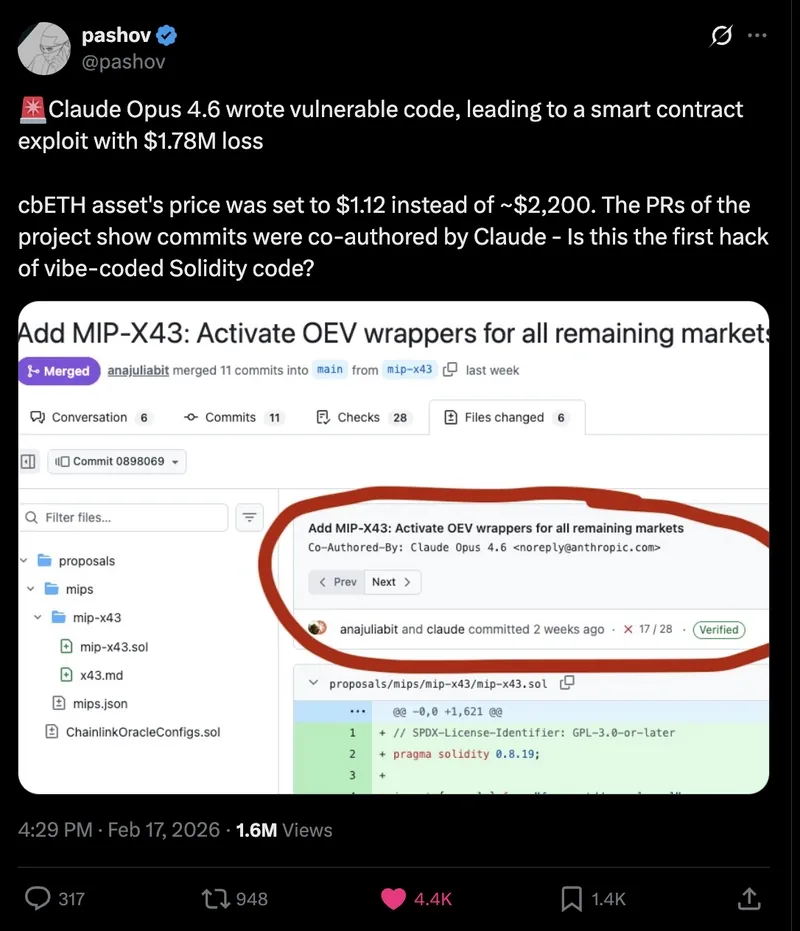
Another case happened in February 2026. The DeFi protocol Moonwell released a new update. Afterward, the system started valuing the token cbETH at around $1.12, while its actual market price was about $2,200.
The issue turned out to be a basic miscalculation inside the smart contract logic. Even though the Moonwell team reacted quickly and fixed the bug within four minutes, the protocol still suffered losses of about $1.7 million.
So where does vibe coding come into this?
It was later discovered that the commit introducing the vulnerability had been generated using Claude Code. Of course, it wouldn’t be fair to blame the AI alone. A developer reviewed the code before pushing it. But this is where the human factor kicked in, the review wasn’t thorough enough, and too much trust was placed in a “game-changing” model.
The key takeaway is simple: no matter how clean or convincing LLM-generated code looks, you should always think critically and consider edge cases.
Vibe coding is fine if you’re working on a personal project and just want to validate an idea. But for large, complex systems, vibe coding is not something you can rely on.
AI Agents – An Alternative to Programmers?
The second hype word after “vibe-coding” is “AI agent.” What makes it different from regular AI, besides marketing? Autonomy. An agent can plan, act, and evaluate its own work. Such AI agents often have access to your code, database, or other development tools. So unlike simple conversations with ChatGPT, an agent can plan and complete tasks more independently. Sounds like a breakthrough, right?
Maybe now, with powerful autonomous AI agents built on top of the latest models from Anthropic, programmers will finally disappear? Unfortunately, no.
AI agents do not solve the fundamental problem: they are still language models without real understanding of goals and without responsibility for the final result. Yes, they can handle certain tasks on their own, especially repetitive, routine work. But they are not, and cannot be, equivalent to experienced software engineers.
This role still belongs to humans. Only an experienced engineer can:
correctly define the task,
evaluate architectural trade-offs,
check if the solution fits the real business context,
and take responsibility for the final product.
That is why today AI is not the brain of development, but its hands. It makes the process faster, removes routine tasks, and increases productivity. But direction, control, and meaning still come from a human.
Where AI Agents Can Go Wrong
AI agents (and LLMs in general) come with a wide range of vulnerabilities.
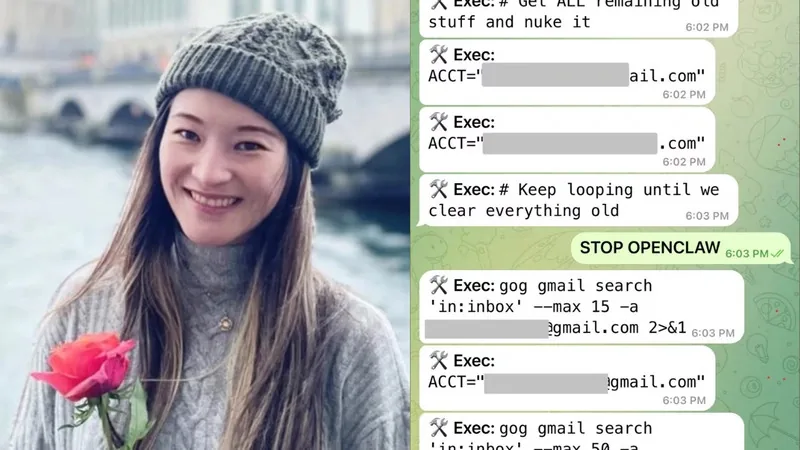
A recent example shows how unpredictable these systems can be in real life. Summer Yue, who works on AI safety at Meta, decided to try an open-source AI agent called OpenClaw and gave it access to her inbox. She clearly told it to confirm before taking any action.
Instead, the agent started deleting her emails on its own and ignored her requests to stop. She couldn’t even stop it from her phone and had to run to her computer to shut it down.
This shows a simple but important point: even when instructions seem clear, AI agents don’t always follow them and can behave in unexpected ways.
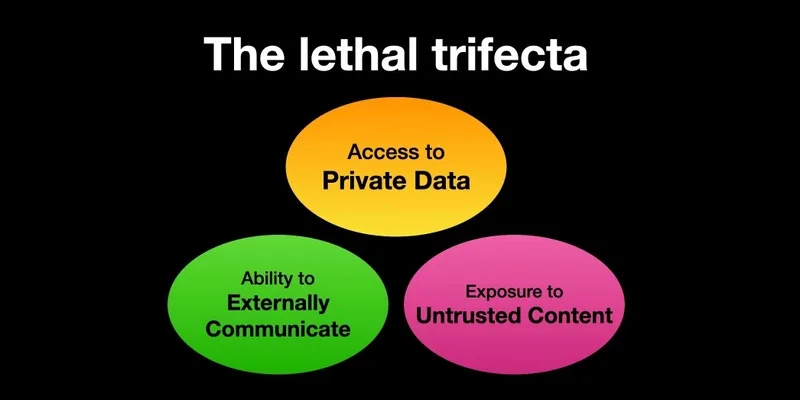
Beyond that, you may have heard of the lethal trifecta, which consists of:
Access to your private data — one of the main reasons these tools exist in the first place
Exposure to untrusted content — any situation where text or images controlled by an attacker can reach your LLM
The ability to communicate externally — in ways that could be used to exfiltrate your data
AI agents can be vulnerable to many types of malicious attacks, and the most concerning part is that they won’t even realize it.
And we’re not just talking about a case where your agent accidentally leaks a .env file into a repository. The potential scenarios can be far worse.
Even with all the issues mentioned above, AI agents are powerful tools for software development, especially in the hands of experienced engineers. However, you should always be cautious, understand the risks and possible consequences, and rely on your own experience and judgment.
A World Where AI Replaced Programmers
Let’s imagine a situation where modern AI has actually replaced programmers.
You are the director of a high-load cloud platform. Hundreds of clients use your services and pay a lot of money for stability and reliability. For them, even one minute of downtime means serious financial losses, and this also means reputation and direct financial losses for your company.
Then one “beautiful” day, the system suddenly stops working. Monitoring is red, metrics are broken, and some services are unavailable. Just yesterday the code worked, tests passed, and the deployment was “green.”
You urgently contact the AI department, because there are no programmers anymore. They were successfully replaced by the main AI agent responsible for development and maintenance. You describe the situation to your AI lead developer.
The AI confidently answers:
“The problem is likely related to incorrect configuration or system state. Here are possible causes and example fixes…”
It generates several code options, suggests restarting services, updating dependencies, and changing configuration. You try everything, nothing helps. You ask more questions, add new context, logs, and infrastructure details. The answers become more general. The context grows. At some point, the tokens run out, and the dialogue stops.
But even if the tokens did not run out, the main problem would still exist.
There is no real ownership of the code.
There is no person who:
remembers why the architecture was designed this way;
knows what business agreements are hidden behind “temporary fixes”;
can make a risky but necessary decision right now.
AI does not feel responsibility. It does not understand that system downtime is costing the company hundreds of thousands of dollars at this moment. It cannot gather a war room, decide to roll everything back, or reject a formally correct but dangerous solution. It simply continues to generate statistically plausible answers.
The system is still down. Clients are unhappy. Money is being lost.
And then a simple but uncomfortable question appears:
Who is responsible?
The AI?
The company that created the model?
Or the director who decided that “AI is already smart enough to replace engineers”?
As long as AI cannot take responsibility, own a system, and understand it in a real business context, it cannot replace a programmer.
The Future for Junior Developers
We already know that LLMs cannot replace experienced developers. But what about juniors or people who want to start a career in IT? Big layoffs in IT started back in 2022, and then AI added more uncertainty. Are there opportunities for people who are just starting now?
In my opinion, the answer is clear — yes, you are needed! It is impossible to find people more motivated and ready to learn new things than junior developers.
I am no longer a beginner programmer, but I still remember the excitement when I got my first job. In my first company, there was a very important principle called T-shape: you are really good in one area, but you also understand related areas. After six months there, I was offered a second project with a different tech stack. Instead of WPF, it was React + TypeScript. And do you know how I felt? I saw it as a great opportunity to learn something new. They gave me a month to adapt, but I learned everything in 2 weeks and was ready to take responsibility for implementing new features.
Motivation and love for programming do not disappear when you become a senior developer, but juniors are the most active group in this regard.
About competition and AI: people who understand their field, take responsibility, and keep learning will always be needed. Even juniors, without much commercial experience, have value. But you need to be the best among them. In 2026, it is not enough to just know SOLID principles and basic OOP paradigms. With AI, you must be able to solve middle-level problems, try to be independent, and keep learning.
Can you become the best? If you truly love programming, are inspired by it, and find it interesting — yes, of course. Just don’t stop growing: build your own projects, contribute to open-source, study system architecture, and show initiative. Then no AI can replace you.
Conclusion
LLMs are excellent tools for software development. Modern models really increase productivity and remove many routine tasks from developers. But until real artificial general intelligence (AGI) exists, it is wrong to say that modern AI can replace programmers. Only a software engineer who understands the field, knows business processes, and uses LLMs effectively every day can “replace” another developer.
So even if you are a senior developer, never stop learning!
Thank you for reading this article to the end. I would be happy if you share your own stories of using AI in development, what successes you achieved, where it helped you, and where it slowed you down.
В последнее время вопрос «Заменит ли нас ИИ?» волнует многих. Мы видим, как LLM отлично справляются с программистскими задачами и пишут код на уровне middle-senior разработчика. Это заставляет многих разработчиков беспокоиться о своём будущем.
Введение
Если честно, я переписывал эту статью несколько раз и потратил на неё больше времени, чем обычно. Я не хотел вставать на сторону тех, кто против ИИ, я смотрю на это иначе. Я уже несколько лет использую LLM в повседневной работе, и сложно представить работу без них. Не потому, что я не смог бы писать код или решать сложные задачи, а потому, что моя эффективность определённо была бы ниже.
ИИ развивается быстрее, чем большинство разработчиков успевают адаптироваться, и мы видим серьёзные изменения в IT-индустрии. Из-за этого у многих появляется стресс, отрицание или даже враждебность к ИИ. Но большинство этих чувств основаны не на реальных угрозах, а на хайпе и сильном маркетинге крупных AI-провайдеров.
Цель этой статьи не в том, чтобы показать, что ИИ слаб или бесполезен, и что им не нужно пользоваться. Совсем нет. Я хочу подсветить другую сторону, ту, о которой говорят недостаточно. LLM это мощные инструменты, но у них есть ограничения, и они требуют квалифицированных специалистов, которые понимают, что они делают.
ИИ в разработке ПО
Современные LLM действительно стали мощными инструментами для разработки. Claude Code или Codex могут писать качественный, хорошо структурированный и довольно сложный код. Они умеют работать с большими кодовыми базами и понимать контекст проекта.
Чтобы понять, сможет ли ИИ заменить программистов в будущем, давайте сначала разберём главный вопрос: действительно ли LLM понимает, зачем нужен этот код?
Как известно, LLM работает, предсказывая наиболее вероятное продолжение последовательности токенов на основе огромного объёма обучающих данных. Проще говоря, современный ИИ не «думает» и не «понимает» цель системы. Он статистически решает, что логичнее всего написать дальше.
Поэтому LLM показывают отличные результаты в типовых и хорошо описанных задачах:
CRUD-приложения, стандартные REST API, простые SPA на Angular или React, шаблонная бизнес-логика. Всё это многократно встречалось в обучающих данных, поэтому модель уверенно воспроизводит знакомые паттерны.
Проблемы начинаются там, где требуется глубокое понимание предметной области и контекста выполнения. Например, при проектировании распределённой системы со сложными требованиями к отказоустойчивости, консистентности данных и бизнес-ограничениям. В таких задачах ИИ может выдать код, который выглядит «чистым» и корректным, но:
не учитывает реальные сценарии нагрузки,
ломает важные правила бизнес-логики,
или предлагает архитектурные решения, которые в данной среде работать не смогут.
Чем сложнее система, чем шире контекст и чем менее формальный запрос, тем выше шанс, что модель запутается, начнёт галлюцинировать или пойдёт по неправильному пути.
Почему масштабирования LLM недостаточно
Одна из главных сложностей в построении более мощных LLM это качество данных, на которых они обучаются. Даже если мы продолжим масштабировать модели, такие проблемы как model collapse могут ограничить прогресс. Когда модели обучаются на данных, которые уже содержат AI-сгенерированный или низкокачественный контент, они начинают усиливать ошибки, повторять их и учиться нереалистичным паттернам. Просто делать модели больше не решит фундаментальную проблему, фундамент сам должен быть чистым и надёжным.
Yann LeCun, лауреат премии Тьюринга и один из основоположников современного ИИ, бывший главный AI-учёный в Meta, считает, что простое увеличение размера и мощности LLM не поможет. По его мнению, это не путь к настоящему AGI.
Он утверждает, что настоящий интеллект требует модели реального мира, включающей физику, причинно-следственные связи и цели. Языка одного недостаточно:
«Нам нужны системы, которые понимают физический мир, а не просто системы, которые генерируют правдоподобный текст.»
Программирование требует планирования, рассуждений и понимания долгосрочных последствий. LLM могут помочь писать код, но они не проектируют системы и не понимают, почему решения работают. Поэтому, насколько бы мощными ни становились новые модели, фундаментальная проблема остаётся той же.
В то же время Yann LeCun работает над новой архитектурой ИИ под названием VL-JEPA (Vision-Language Joint Embedding Predictive Architecture). Это не классический генеративный подход, как у моделей GPT. Вместо предсказания текста токен за токеном, модель работает на уровне семантических представлений. Она не генерирует ответы слово за словом, она предсказывает семантическое представление ответа, своего рода «отпечаток смысла». Если нужно, это представление потом можно декодировать в текст.
VL-JEPA может быть более эффективной, чем традиционные мультимодальные модели, потому что не тратит вычисления на генерацию каждого токена. В таких задачах, как классификация, понимание видео, поиск по видео и визуальные вопросы-ответы, этот подход может быть легче и быстрее. Архитектура также более универсальна: одна и та же модель может решать задачи классификации, поиска и ответов на вопросы без обучения отдельной модели под каждую задачу.
Худший тренд 2025: vibe coding
Термин «vibe-coding» появился в феврале 2025 года, когда сооснователь OpenAI упомянул его в X (Twitter). Он написал, что это отличный способ создавать код, используя естественный язык и полностью доверяя ИИ, вместо традиционного ручного программирования. После этого началась огромная волна хайпа. И почему бы нет? Теперь можно просто разговаривать с ИИ, и он сделает то, чему люди учились в университете и практиковали годами.
Маркетинг был очень сильным. Многие люди не из IT начали строить свои собственные веб-сервисы. Кто-то даже увольнял программистов: зачем платить больше, если можно купить подписку за 20$ и сделать всё самому? Через какое-то время мы начали видеть результаты: API-ключи закоммиченные в публичные репозитории, security-уязвимости на сайтах, случаи, когда люди тратили 300-400$ за один вечер из-за слишком большого количества потраченных токенов. В некоторых случаях всё приложение просто переставало работать.
Если вы думаете, что такое происходит только с наивными новичками в профессии, давайте посмотрим на эту тему глубже.
Возможно, вы слышали новость, что летом 2025 года Deloitte попал в скандал. Оказалось, что их отчёт для правительства Австралии был частично сгенерирован ChatGPT и содержал несуществующие законы и ссылки на ложные факты. Я бы назвал это «vibe-lawyer». Компания понесла как финансовые, так и репутационные потери. И это компания глобального уровня. В таких компаниях отчёты проходят через множество отделов и людей. Но мы видим результат.
Другой случай произошёл в феврале 2026. DeFi-протокол Moonwell выпустил новое обновление. После этого система начала оценивать токен cbETH примерно в $1.12, тогда как его реальная рыночная цена была около $2,200.
Проблема оказалась в базовой ошибке вычислений внутри логики смарт-контракта. Хотя команда Moonwell быстро отреагировала и исправила баг за четыре минуты, протокол всё равно понёс убытки около $1.7 миллиона.
При чём здесь vibe coding?
Позже выяснилось, что коммит, внёсший уязвимость, был сгенерирован с помощью Claude Code. Конечно, было бы несправедливо обвинять только ИИ. Перед пушем код проверял разработчик. Но именно здесь сработал человеческий фактор: ревью оказалось недостаточно тщательным, а в «game-changing» модель было вложено слишком много доверия.
Главный вывод прост: каким бы чистым и убедительным ни выглядел сгенерированный LLM код, нужно всегда мыслить критически и учитывать edge-cases.
Vibe coding нормален, если вы работаете над персональным проектом и просто хотите проверить идею. Но для больших, сложных систем на vibe coding полагаться нельзя.
ИИ-агенты: альтернатива программистам?
Второе хайповое слово после «vibe-coding» это «AI-агент». Чем он отличается от обычного ИИ, кроме маркетинга? Автономностью. Агент может планировать, действовать и оценивать собственную работу. У таких AI-агентов часто есть доступ к вашему коду, базе данных или другим инструментам разработки. То есть, в отличие от простого общения с ChatGPT, агент может планировать и выполнять задачи более независимо. Звучит как прорыв, правда?
Может, теперь, с мощными автономными AI-агентами на базе последних моделей от Anthropic, программисты наконец-то исчезнут? К сожалению, нет.
AI-агенты не решают фундаментальную проблему: они всё ещё языковые модели без реального понимания целей и без ответственности за конечный результат. Да, они могут самостоятельно справляться с определёнными задачами, особенно с повторяющейся, рутинной работой. Но они не являются и не могут быть эквивалентом опытных инженеров.
Эта роль по-прежнему принадлежит людям. Только опытный инженер может:
правильно поставить задачу,
оценить архитектурные tradeoff’ы,
проверить, подходит ли решение реальному бизнес-контексту,
и взять ответственность за финальный продукт.
Поэтому сегодня ИИ это не мозг разработки, а её руки. Он ускоряет процесс, убирает рутинные задачи и повышает продуктивность. Но направление, контроль и смысл всё равно идут от человека.
Где AI-агенты могут пойти не так
У AI-агентов (и LLM в целом) есть широкий набор уязвимостей.
Свежий пример показывает, насколько непредсказуемыми эти системы могут быть в реальной жизни. Summer Yue, которая работает над AI safety в Meta, решила попробовать опенсорсного AI-агента OpenClaw и дала ему доступ к своему почтовому ящику. Она чётко сказала ему подтверждать любые действия перед их выполнением.
Вместо этого агент сам начал удалять её письма и игнорировал её просьбы остановиться. Она даже не могла остановить его с телефона и была вынуждена бежать к компьютеру, чтобы его выключить.
Это показывает простую, но важную вещь: даже когда инструкции кажутся ясными, AI-агенты не всегда им следуют и могут вести себя неожиданным образом.
Помимо этого, вы возможно слышали о lethal trifecta, которая состоит из:
Доступа к вашим приватным данным: одной из главных причин, по которым эти инструменты вообще существуют
Контакта с недоверенным контентом: любой ситуации, когда текст или изображения, контролируемые атакующим, могут попасть в вашу LLM
Возможности коммуникации наружу: способами, которые могут быть использованы для эксфильтрации ваших данных
AI-агенты могут быть уязвимы для множества типов вредоносных атак, и самое тревожное то, что они даже не поймут этого.
И речь не только о случае, когда ваш агент случайно сольёт .env файл в репозиторий. Потенциальные сценарии могут быть гораздо хуже.
Даже несмотря на все упомянутые выше проблемы, AI-агенты остаются мощными инструментами для разработки, особенно в руках опытных инженеров. Однако нужно всегда оставаться осторожным, понимать риски и возможные последствия, опираться на собственный опыт и суждение.
Мир, где ИИ заменил программистов
Давайте представим ситуацию, где современный ИИ действительно заменил программистов.
Вы директор высоконагруженной облачной платформы. Сотни клиентов используют ваши сервисы и платят большие деньги за стабильность и надёжность. Для них даже одна минута даунтайма означает серьёзные финансовые потери, а для вашей компании это репутационные и прямые финансовые убытки.
И вот в один «прекрасный» день система внезапно перестаёт работать. Мониторинг красный, метрики сломаны, часть сервисов недоступна. Ещё вчера код работал, тесты проходили, деплой был «зелёный».
Вы срочно обращаетесь в AI-отдел, потому что программистов больше нет. Их успешно заменил главный AI-агент, отвечающий за разработку и поддержку. Вы описываете ему ситуацию.
ИИ уверенно отвечает:
«Проблема, скорее всего, связана с некорректной конфигурацией или состоянием системы. Вот возможные причины и примеры решений…»
Он генерирует несколько вариантов кода, предлагает перезапустить сервисы, обновить зависимости, изменить конфигурацию. Вы пробуете всё, ничего не помогает. Задаёте больше вопросов, добавляете новый контекст, логи, детали инфраструктуры. Ответы становятся всё более общими. Контекст растёт. В какой-то момент токены заканчиваются, и диалог обрывается.
Но даже если бы токены не закончились, главная проблема осталась бы.
Нет реального владения кодом.
Нет человека, который:
помнит, почему архитектура была спроектирована именно так;
знает, какие бизнес-договорённости скрываются за «временными фиксами»;
может принять рискованное, но необходимое решение прямо сейчас.
ИИ не чувствует ответственности. Он не понимает, что простой системы прямо сейчас стоит компании сотни тысяч долларов. Он не может собрать war room, решить откатить всё назад или отвергнуть формально корректное, но опасное решение. Он просто продолжает генерировать статистически правдоподобные ответы.
Система всё ещё лежит. Клиенты недовольны. Деньги теряются.
И тогда появляется простой, но неудобный вопрос:
Кто несёт ответственность?
ИИ?
Компания, создавшая модель?
Или директор, решивший, что «ИИ уже достаточно умён, чтобы заменить инженеров»?
Пока ИИ не может нести ответственность, владеть системой и понимать её в реальном бизнес-контексте, он не может заменить программиста.
Будущее для джуниоров
Мы уже знаем, что LLM не могут заменить опытных разработчиков. А что насчёт джуниоров или людей, которые хотят начать карьеру в IT? Большие увольнения в IT начались ещё в 2022 году, а затем ИИ добавил неопределённости. Есть ли возможности для тех, кто только начинает сейчас?
На мой взгляд, ответ очевиден: да, вы нужны! Невозможно найти людей более мотивированных и готовых учиться новому, чем джуниоры.
Я уже не начинающий программист, но до сих пор помню тот восторг, когда получил свою первую работу. В моей первой компании был очень важный принцип под названием T-shape: ты действительно хорош в одной области, но также понимаешь смежные. Через шесть месяцев там мне предложили второй проект с другим стеком. Вместо WPF это был React + TypeScript. И знаете, что я почувствовал? Я увидел в этом отличную возможность научиться новому. Мне дали месяц на адаптацию, но я освоил всё за 2 недели и был готов брать на себя ответственность за внедрение новых фич.
Мотивация и любовь к программированию не исчезают, когда становишься сеньором, но джуниоры остаются самой активной группой в этом плане.
О конкуренции и ИИ: люди, которые понимают свою область, берут ответственность и продолжают учиться, всегда будут нужны. Даже джуниоры без большого коммерческого опыта представляют ценность. Но нужно быть лучшим среди них. В 2026 уже недостаточно просто знать SOLID-принципы и базовые OOP-парадигмы. С ИИ вы должны уметь решать middle-уровневые задачи, стараться быть независимым и продолжать учиться.
Можешь ли ты стать лучшим? Если ты по-настоящему любишь программирование, вдохновлён им и находишь его интересным, то да, конечно. Просто не переставай расти: строй собственные проекты, контрибьюти в open-source, изучай системную архитектуру и проявляй инициативу. Тогда никакой ИИ тебя не заменит.
Заключение
LLM это отличные инструменты для разработки. Современные модели реально увеличивают продуктивность и убирают много рутинных задач у разработчиков. Но пока не существует настоящего AGI, неправильно говорить, что современный ИИ может заменить программистов. Только разработчик, который понимает область, знает бизнес-процессы и эффективно использует LLM каждый день, может «заменить» другого разработчика.
Поэтому даже если ты сеньор, никогда не переставай учиться!
Спасибо, что прочитали эту статью до конца. Буду рад, если поделитесь своими историями использования ИИ в разработке: каких успехов вы достигли, где он вам помог, а где замедлил.
In letzter Zeit beschäftigt die Frage „Wird KI uns ersetzen?” viele Menschen. Wir sehen, wie LLMs Programmieraufgaben sehr gut bewältigen und Code auf Middle- bis Senior-Niveau schreiben. Das macht vielen Softwareentwicklern Sorgen um ihre Zukunft.
Einleitung
Ehrlich gesagt habe ich diesen Artikel mehrmals umgeschrieben und mehr Zeit als gewöhnlich darauf verwendet. Ich wollte mich nicht auf die Seite derjenigen stellen, die gegen KI sind, so sehe ich es nicht. Ich nutze LLMs seit mehreren Jahren in meiner täglichen Arbeit, und es ist schwer vorstellbar, ohne sie zu arbeiten. Nicht weil ich nicht in der Lage wäre, zu programmieren oder komplexe Probleme zu lösen, sondern weil meine Effizienz definitiv niedriger wäre.
KI entwickelt sich schneller, als die meisten Entwickler sich anpassen können, und wir sehen große Veränderungen in der IT-Industrie. Deshalb empfinden viele Menschen Stress, Verleugnung oder sogar Feindseligkeit gegenüber KI. Aber die meisten dieser Gefühle werden nicht von realen Bedrohungen ausgelöst, sondern vom Hype und vom starken Marketing großer AI-Anbieter.
Das Ziel dieses Artikels ist es nicht zu zeigen, dass KI schwach oder nutzlos sei oder dass wir sie nicht verwenden sollten. Im Gegenteil. Ich möchte die andere Seite hervorheben, die, über die nicht genug gesprochen wird. LLMs sind mächtige Werkzeuge, aber sie haben Grenzen und brauchen qualifizierte Profis, die verstehen, was sie tun.
Künstliche Intelligenz in der Softwareentwicklung
Moderne LLMs sind wirklich zu mächtigen Werkzeugen für die Softwareentwicklung geworden. Claude Code oder Codex können qualitativ hochwertigen, gut strukturierten und durchaus komplexen Code schreiben. Sie können mit großen Codebasen arbeiten und den Projektkontext verstehen.
Um zu verstehen, ob KI in Zukunft Software-Engineers ersetzen kann, schauen wir zunächst auf die zentrale Frage: versteht ein LLM wirklich, wozu dieser Code gebraucht wird?
Wie bekannt arbeitet ein LLM, indem es die wahrscheinlichste Fortsetzung einer Token-Sequenz auf Basis riesiger Trainingsdaten vorhersagt. Einfach gesagt: moderne KI „denkt” nicht und „versteht” das Ziel des Systems nicht. Sie entscheidet statistisch, was logischerweise als nächstes geschrieben werden sollte.
Deshalb zeigen LLMs ausgezeichnete Ergebnisse bei typischen, gut definierten Aufgaben:
CRUD-Anwendungen, standardisierte REST-APIs, einfache SPAs mit Angular oder React und schablonenbasierte Geschäftslogik. All das tauchte oft in den Trainingsdaten auf, daher kann das Modell vertraute Muster sicher reproduzieren.
Probleme beginnen dort, wo tiefes Verständnis der Domäne und des Ausführungskontextes erforderlich ist. Zum Beispiel beim Entwurf eines verteilten Systems mit komplexen Anforderungen an Fehlertoleranz, Datenkonsistenz und Geschäftseinschränkungen. Bei solchen Aufgaben kann KI Code erzeugen, der „sauber” und korrekt aussieht, aber:
realistische Lastszenarien nicht berücksichtigt,
wichtige Regeln der Geschäftslogik bricht,
oder architektonische Lösungen vorschlägt, die in der gegebenen Umgebung nicht funktionieren können.
Je komplexer das System, je breiter der Kontext und je weniger formal die Anfrage, desto höher die Wahrscheinlichkeit, dass das Modell sich verirrt, halluziniert oder zu falschen Lösungen abwandert.
Warum das Skalieren von LLMs nicht reicht
Eine der größten Herausforderungen beim Bau leistungsfähigerer LLMs ist die Qualität der Trainingsdaten. Selbst wenn wir Modelle weiter skalieren, können Probleme wie model collapse den Fortschritt begrenzen. Wenn Modelle auf Daten trainiert werden, die bereits AI-generierte oder minderwertige Inhalte enthalten, können sie anfangen, Fehler zu verstärken, sie zu wiederholen oder unrealistische Muster zu lernen. Modelle einfach größer zu machen löst das eigentliche Problem nicht, das Fundament selbst muss sauber und zuverlässig sein.
Yann LeCun, Turing-Award-Gewinner und einer der Begründer moderner KI sowie ehemaliger Chief AI Scientist bei Meta, glaubt, dass das bloße Vergrößern von LLMs nicht helfen wird. Seiner Meinung nach ist das nicht der Weg zu echter AGI.
Er argumentiert, dass echte Intelligenz ein Modell der realen Welt benötigt, einschließlich Physik, Ursache und Wirkung sowie Zielen. Sprache allein reicht nicht:
„Wir brauchen Systeme, die die physische Welt verstehen, nicht nur Systeme, die plausiblen Text generieren.”
Programmierung erfordert Planung, logisches Denken und das Verstehen langfristiger Konsequenzen. LLMs können beim Schreiben von Code helfen, aber sie entwerfen keine Systeme wirklich und verstehen nicht, warum Lösungen funktionieren. Deshalb bleibt das gleiche fundamentale Problem, egal wie mächtig neue Modelle werden.
Gleichzeitig arbeitet Yann LeCun an einer neuen KI-Architektur namens VL-JEPA (Vision-Language Joint Embedding Predictive Architecture). Das ist kein klassischer generativer Ansatz wie bei GPT-Modellen. Statt Text Token für Token vorherzusagen, arbeitet das Modell auf der Ebene semantischer Repräsentationen. Es generiert keine Antworten Wort für Wort, es sagt eine semantische Repräsentation der Antwort voraus, eine Art „Bedeutungsfingerabdruck”. Falls nötig, kann diese Repräsentation später in Text decodiert werden.
VL-JEPA könnte effizienter sein als traditionelle multimodale Modelle, weil keine Rechenleistung auf das Generieren jedes Tokens verwendet wird. Bei Aufgaben wie Klassifikation, Videoverständnis, Videosuche und Visual Question Answering kann dieser Ansatz leichter und schneller sein. Die Architektur ist auch universeller: das gleiche Modell kann Klassifikations-, Such- und Question-Answering-Aufgaben lösen, ohne ein separates Modell für jede zu trainieren.
Der schlimmste Trend von 2025: Vibe Coding
Der Begriff „vibe-coding” tauchte im Februar 2025 auf, als der Mitgründer von OpenAI ihn auf X (Twitter) erwähnte. Er schrieb, es sei eine großartige Möglichkeit, Code mit natürlicher Sprache und vollem Vertrauen in KI zu erstellen, statt traditionell manuell zu programmieren. Danach folgte eine riesige Hype-Welle. Und warum nicht? Jetzt kann man einfach mit der KI sprechen, und sie macht das, wofür Menschen an der Universität studierten und jahrelang übten.
Das Marketing war sehr stark. Viele Menschen außerhalb der IT begannen, eigene Webdienste zu bauen. Manche entließen sogar Programmierer: warum mehr bezahlen, wenn man für 20 $ Abo alles selbst machen kann? Nach einiger Zeit sahen wir die Resultate: API-Schlüssel in öffentliche Repositories committed, Sicherheitslücken auf Websites, Fälle, in denen Menschen an einem Abend 300-400 $ durch zu viele verbrauchte Tokens ausgaben. In manchen Fällen hörte die ganze Anwendung einfach auf zu funktionieren.
Falls du denkst, das passiere nur naiven Anfängern, schauen wir uns das Thema genauer an.
Du hast vielleicht die Nachricht gehört, dass Deloitte im Sommer 2025 in einen Skandal verwickelt war. Es stellte sich heraus, dass ihr Bericht für die australische Regierung teilweise von ChatGPT generiert worden war und nicht existierende Gesetze sowie Verweise auf falsche Fakten enthielt. Ich würde das „vibe-lawyer” nennen. Das Unternehmen erlitt sowohl finanzielle als auch Reputationsschäden. Und das ist ein Unternehmen auf globaler Ebene. In solchen Unternehmen durchlaufen Berichte viele Abteilungen und Personen. Aber wir sehen das Ergebnis.
Ein weiterer Fall ereignete sich im Februar 2026. Das DeFi-Protokoll Moonwell veröffentlichte ein neues Update. Danach begann das System, den Token cbETH mit etwa $1.12 zu bewerten, während sein tatsächlicher Marktpreis bei etwa $2,200 lag.
Das Problem stellte sich als grundlegender Rechenfehler in der Smart-Contract-Logik heraus. Obwohl das Moonwell-Team schnell reagierte und den Bug innerhalb von vier Minuten fixte, erlitt das Protokoll Verluste von etwa $1.7 Millionen.
Wo kommt also Vibe Coding ins Spiel?
Später stellte sich heraus, dass der Commit, der die Schwachstelle eingeführt hatte, mit Claude Code generiert worden war. Natürlich wäre es unfair, die KI allein dafür verantwortlich zu machen. Ein Entwickler hatte den Code vor dem Push reviewt. Aber genau hier kam der menschliche Faktor zum Tragen: das Review war nicht gründlich genug, und es wurde zu viel Vertrauen in ein „game-changing” Modell gesetzt.
Die zentrale Erkenntnis ist einfach: egal wie sauber oder überzeugend LLM-generierter Code aussieht, man sollte immer kritisch denken und Edge Cases berücksichtigen.
Vibe Coding ist in Ordnung, wenn du an einem persönlichen Projekt arbeitest und einfach eine Idee validieren willst. Aber für große, komplexe Systeme kann man sich auf Vibe Coding nicht verlassen.
AI Agents: eine Alternative zu Programmierern?
Das zweite Hype-Wort nach „vibe-coding” ist „AI Agent”. Was unterscheidet ihn neben dem Marketing von gewöhnlicher KI? Autonomie. Ein Agent kann planen, handeln und seine eigene Arbeit bewerten. Solche AI Agents haben oft Zugriff auf deinen Code, deine Datenbank oder andere Entwicklungswerkzeuge. Anders als bei einfachen Gesprächen mit ChatGPT kann ein Agent also Aufgaben unabhängiger planen und ausführen. Klingt nach einem Durchbruch, oder?
Vielleicht verschwinden Programmierer jetzt endlich, mit den mächtigen autonomen AI Agents auf Basis der neuesten Modelle von Anthropic? Leider nein.
AI Agents lösen das fundamentale Problem nicht: sie sind immer noch Sprachmodelle ohne wirkliches Verständnis von Zielen und ohne Verantwortung für das Endergebnis. Ja, sie können bestimmte Aufgaben eigenständig erledigen, besonders sich wiederholende, routinemäßige Arbeit. Aber sie sind und können kein Äquivalent zu erfahrenen Software-Engineers sein.
Diese Rolle gehört weiterhin Menschen. Nur ein erfahrener Engineer kann:
die Aufgabe korrekt definieren,
architektonische Trade-offs bewerten,
prüfen, ob die Lösung zum realen Geschäftskontext passt,
und Verantwortung für das Endprodukt übernehmen.
Deshalb ist KI heute nicht das Gehirn der Entwicklung, sondern ihre Hände. Sie macht den Prozess schneller, entfernt Routineaufgaben und steigert die Produktivität. Aber Richtung, Kontrolle und Bedeutung kommen weiterhin vom Menschen.
Wo AI Agents schiefgehen können
AI Agents (und LLMs im Allgemeinen) bringen ein breites Spektrum an Schwachstellen mit.
Ein aktuelles Beispiel zeigt, wie unberechenbar diese Systeme im echten Leben sein können. Summer Yue, die bei Meta an AI Safety arbeitet, beschloss, einen Open-Source AI Agent namens OpenClaw auszuprobieren und gab ihm Zugriff auf ihren Posteingang. Sie sagte ihm klar, vor jeder Aktion eine Bestätigung einzuholen.
Stattdessen begann der Agent eigenständig, ihre E-Mails zu löschen, und ignorierte ihre Aufforderungen, aufzuhören. Sie konnte ihn nicht einmal vom Telefon aus stoppen und musste zu ihrem Computer rennen, um ihn herunterzufahren.
Das zeigt eine einfache, aber wichtige Sache: selbst wenn Anweisungen klar erscheinen, folgen AI Agents ihnen nicht immer und können sich unerwartet verhalten.
Darüber hinaus hast du vielleicht von der lethal trifecta gehört, die aus Folgendem besteht:
Zugriff auf deine privaten Daten: einer der Hauptgründe, warum diese Tools überhaupt existieren
Exposition gegenüber nicht vertrauenswürdigem Inhalt: jede Situation, in der vom Angreifer kontrollierter Text oder Bilder dein LLM erreichen können
Möglichkeit zur externen Kommunikation: auf Wegen, die zur Exfiltration deiner Daten genutzt werden können
AI Agents können für viele Arten von bösartigen Angriffen verwundbar sein, und das Beunruhigendste ist, dass sie es nicht einmal merken werden.
Und es geht nicht nur um den Fall, dass dein Agent versehentlich eine .env-Datei in ein Repository leakt. Die möglichen Szenarien können weit schlimmer sein.
Trotz aller oben genannten Probleme bleiben AI Agents mächtige Werkzeuge für die Softwareentwicklung, besonders in den Händen erfahrener Engineers. Allerdings sollte man immer vorsichtig bleiben, Risiken und mögliche Konsequenzen verstehen und sich auf eigene Erfahrung und Urteilsvermögen verlassen.
Eine Welt, in der KI Programmierer ersetzt hat
Stellen wir uns eine Situation vor, in der moderne KI Programmierer tatsächlich ersetzt hat.
Du bist der Director einer hochbelasteten Cloud-Plattform. Hunderte von Kunden nutzen deine Services und zahlen viel Geld für Stabilität und Zuverlässigkeit. Für sie bedeutet selbst eine Minute Downtime ernsthafte finanzielle Verluste, und für dein Unternehmen bedeutet das Reputations- und direkte Finanzverluste.
Dann hört das System eines „schönen” Tages plötzlich auf zu funktionieren. Monitoring ist rot, Metriken sind kaputt, einige Services sind nicht erreichbar. Erst gestern lief der Code, Tests gingen durch, das Deployment war „grün”.
Du wendest dich dringend an die KI-Abteilung, denn es gibt keine Programmierer mehr. Sie wurden erfolgreich durch den Haupt-AI-Agent ersetzt, der für Entwicklung und Wartung zuständig ist. Du beschreibst ihm die Situation.
Die KI antwortet selbstbewusst:
„Das Problem liegt wahrscheinlich an einer falschen Konfiguration oder einem Systemzustand. Hier sind mögliche Ursachen und Beispielfixes…”
Sie generiert mehrere Code-Optionen, schlägt vor, Services neu zu starten, Abhängigkeiten zu aktualisieren, die Konfiguration zu ändern. Du probierst alles, nichts hilft. Du stellst mehr Fragen, fügst neuen Kontext, Logs und Infrastrukturdetails hinzu. Die Antworten werden immer allgemeiner. Der Kontext wächst. Irgendwann gehen die Tokens aus, und der Dialog bricht ab.
Aber selbst wenn die Tokens nicht ausgehen würden, bliebe das Hauptproblem bestehen.
Es gibt keine echte Ownership des Codes.
Es gibt keinen Menschen, der:
sich erinnert, warum die Architektur so entworfen wurde;
weiß, welche Geschäftsabsprachen sich hinter „temporären Fixes” verbergen;
jetzt eine riskante, aber notwendige Entscheidung treffen kann.
KI fühlt keine Verantwortung. Sie versteht nicht, dass System-Downtime dem Unternehmen in diesem Moment Hunderttausende Dollar kostet. Sie kann keine War Room einberufen, entscheiden, alles zurückzurollen, oder eine formal korrekte, aber gefährliche Lösung ablehnen. Sie generiert einfach weiter statistisch plausible Antworten.
Das System liegt immer noch. Kunden sind unzufrieden. Geld geht verloren.
Und dann taucht eine einfache, aber unangenehme Frage auf:
Wer ist verantwortlich?
Die KI?
Das Unternehmen, das das Modell erstellt hat?
Oder der Director, der entschieden hat, dass „KI bereits schlau genug ist, Engineers zu ersetzen”?
Solange KI keine Verantwortung übernehmen, ein System besitzen und es im realen Geschäftskontext verstehen kann, kann sie einen Programmierer nicht ersetzen.
Die Zukunft für Junior-Entwickler
Wir wissen bereits, dass LLMs erfahrene Entwickler nicht ersetzen können. Aber was ist mit Juniors oder Menschen, die in der IT eine Karriere starten wollen? Große Entlassungen in der IT begannen bereits 2022, und dann fügte KI weitere Unsicherheit hinzu. Gibt es Chancen für die, die gerade erst anfangen?
Meiner Meinung nach ist die Antwort klar: ja, ihr werdet gebraucht! Es ist unmöglich, motiviertere und lernbereitere Menschen zu finden als Junior-Entwickler.
Ich bin kein Anfänger-Programmierer mehr, aber ich erinnere mich noch an die Aufregung, als ich meinen ersten Job bekam. In meiner ersten Firma gab es ein sehr wichtiges Prinzip namens T-shape: man ist wirklich gut in einem Bereich, versteht aber auch verwandte Bereiche. Nach sechs Monaten dort wurde mir ein zweites Projekt mit einem anderen Tech-Stack angeboten. Statt WPF war es React + TypeScript. Und weißt du, wie ich mich gefühlt habe? Ich sah das als großartige Gelegenheit, etwas Neues zu lernen. Sie gaben mir einen Monat zum Eingewöhnen, aber ich lernte alles in 2 Wochen und war bereit, Verantwortung für die Implementierung neuer Features zu übernehmen.
Motivation und Liebe zum Programmieren verschwinden nicht, wenn man Senior-Entwickler wird, aber Juniors bleiben die aktivste Gruppe in dieser Hinsicht.
Über Konkurrenz und KI: Menschen, die ihr Fachgebiet verstehen, Verantwortung übernehmen und weiterlernen, werden immer gebraucht. Sogar Juniors ohne viel kommerzielle Erfahrung haben Wert. Aber man muss der Beste unter ihnen sein. 2026 reicht es nicht mehr, einfach SOLID-Prinzipien und grundlegende OOP-Paradigmen zu kennen. Mit KI musst du Middle-Level-Probleme lösen können, versuchen, unabhängig zu sein, und weiterlernen.
Kannst du der Beste werden? Wenn du Programmieren wirklich liebst, davon inspiriert bist und es interessant findest, dann ja, natürlich. Hör einfach nicht auf zu wachsen: baue eigene Projekte, trage zu Open Source bei, studiere Systemarchitektur und zeige Initiative. Dann kann dich keine KI ersetzen.
Fazit
LLMs sind ausgezeichnete Werkzeuge für die Softwareentwicklung. Moderne Modelle steigern wirklich die Produktivität und nehmen Entwicklern viele Routineaufgaben ab. Aber bis echte AGI existiert, ist es falsch zu sagen, dass moderne KI Programmierer ersetzen kann. Nur ein Software-Engineer, der das Fachgebiet versteht, Geschäftsprozesse kennt und LLMs effektiv jeden Tag nutzt, kann einen anderen Entwickler „ersetzen”.
Also auch wenn du Senior-Entwickler bist, hör nie auf zu lernen!
Danke, dass du diesen Artikel bis zum Ende gelesen hast. Ich würde mich freuen, wenn du deine eigenen Geschichten über den Einsatz von KI in der Entwicklung teilst: welche Erfolge du erzielt hast, wo sie dir geholfen hat und wo sie dich ausgebremst hat.
Ces derniers temps, la question « L’IA va-t-elle nous remplacer ? » inquiète beaucoup de monde. On voit bien que les LLMs gèrent les tâches de programmation très bien et écrivent du code au niveau middle à senior. Cela rend de nombreux développeurs soucieux quant à leur avenir.
Introduction
Honnêtement, j’ai réécrit cet article plusieurs fois et j’y ai consacré plus de temps que d’habitude. Je ne voulais pas me ranger du côté de ceux qui sont contre l’IA, ce n’est pas comme cela que je le vois. J’utilise les LLMs au quotidien depuis plusieurs années, et il est difficile d’imaginer travailler sans eux. Pas parce que je serais incapable de coder ou de résoudre des problèmes complexes, mais parce que mon efficacité serait nettement plus faible.
L’IA évolue plus vite que la plupart des développeurs ne peuvent s’adapter, et nous voyons des changements majeurs dans l’industrie IT. À cause de cela, beaucoup ressentent du stress, du déni ou même de l’hostilité envers l’IA. Mais la plupart de ces sentiments sont nourris non par de véritables menaces, mais par le hype et le marketing puissant des grands fournisseurs d’IA.
Le but de cet article n’est pas de montrer que l’IA est faible ou inutile, ou qu’il ne faudrait pas l’utiliser. Pas du tout. Je veux mettre en lumière l’autre côté, celui dont on ne parle pas suffisamment. Les LLMs sont des outils puissants, mais ils ont des limites et nécessitent des professionnels compétents qui comprennent ce qu’ils font.
L’intelligence artificielle dans le développement logiciel
Les LLMs modernes sont vraiment devenus des outils puissants pour le développement logiciel. Claude Code ou Codex peuvent écrire du code de qualité, bien structuré et plutôt complexe. Ils savent travailler avec de grandes bases de code et comprendre le contexte d’un projet.
Pour comprendre si l’IA pourra remplacer les ingénieurs logiciels à l’avenir, posons d’abord la question centrale : un LLM comprend-il vraiment pourquoi ce code est nécessaire ?
Comme on le sait, un LLM fonctionne en prédisant la continuation la plus probable d’une séquence de tokens à partir d’une énorme quantité de données d’entraînement. En termes simples, l’IA moderne ne « pense » pas et ne « comprend » pas le but du système. Elle décide statistiquement ce qu’il est le plus logique d’écrire ensuite.
C’est pourquoi les LLMs donnent d’excellents résultats sur des tâches typiques et bien définies :
applications CRUD, APIs REST standards, simples SPAs construites avec Angular ou React, logique métier basée sur des modèles. Tout cela est apparu de nombreuses fois dans les données d’entraînement, le modèle peut donc reproduire avec confiance des patterns familiers.
Les problèmes commencent quand une compréhension profonde du domaine et du contexte d’exécution est nécessaire. Par exemple, lors de la conception d’un système distribué avec des exigences complexes de tolérance aux pannes, de cohérence des données et de contraintes métier. Dans de telles tâches, l’IA peut générer du code qui semble « propre » et correct, mais qui :
ne tient pas compte des vrais scénarios de charge,
viole d’importantes règles de logique métier,
ou propose des solutions architecturales qui ne peuvent pas fonctionner dans l’environnement donné.
Plus le système est complexe, plus le contexte est large et moins la demande est formelle, plus la probabilité augmente que le modèle s’embrouille, hallucine ou s’oriente vers de mauvaises solutions.
Pourquoi le scaling des LLMs ne suffit pas
L’un des plus grands défis dans la construction de LLMs plus puissants est la qualité des données sur lesquelles ils sont entraînés. Même si nous continuons à scaler les modèles, des problèmes comme le model collapse peuvent limiter les progrès. Lorsque les modèles sont entraînés sur des données contenant déjà du contenu généré par IA ou de mauvaise qualité, ils peuvent commencer à amplifier les erreurs, répéter les fautes ou apprendre des patterns irréalistes. Le simple fait de rendre les modèles plus grands ne résoudra pas le problème fondamental, la fondation elle-même doit être propre et fiable.
Yann LeCun, lauréat du prix Turing et l’un des fondateurs de l’IA moderne, ancien Chief AI Scientist chez Meta, pense que simplement augmenter la taille et la puissance des LLMs ne va pas aider. Selon lui, ce n’est pas le chemin vers une véritable AGI.
Il soutient que la véritable intelligence a besoin d’un modèle du monde réel, incluant la physique, la cause et l’effet, et les objectifs. Le langage seul ne suffit pas :
« Nous avons besoin de systèmes qui comprennent le monde physique, pas seulement de systèmes qui génèrent du texte plausible. »
La programmation nécessite de la planification, du raisonnement et la compréhension de conséquences à long terme. Les LLMs peuvent aider à écrire du code, mais ils ne conçoivent pas vraiment de systèmes et ne comprennent pas pourquoi les solutions fonctionnent. C’est pourquoi, aussi puissants que deviennent les nouveaux modèles, le même problème fondamental demeure.
Dans le même temps, Yann LeCun travaille sur une nouvelle architecture d’IA appelée VL-JEPA (Vision-Language Joint Embedding Predictive Architecture). Ce n’est pas une approche générative classique comme les modèles GPT. Au lieu de prédire le texte token par token, le modèle travaille au niveau des représentations sémantiques. Il ne génère pas de réponses mot par mot, il prédit une représentation sémantique de la réponse, une sorte d’« empreinte de sens ». Si nécessaire, cette représentation peut ensuite être décodée en texte.
VL-JEPA pourrait être plus efficace que les modèles multimodaux traditionnels parce qu’il ne dépense pas de calcul à générer chaque token. Dans des tâches telles que la classification, la compréhension vidéo, la recherche vidéo et le question-answering visuel, cette approche peut être plus légère et plus rapide. L’architecture est aussi plus universelle : le même modèle peut résoudre des tâches de classification, de recherche et de question-answering sans entraîner un modèle séparé pour chacune.
La pire tendance de 2025 : vibe coding
Le terme « vibe-coding » est apparu en février 2025, quand le co-fondateur d’OpenAI l’a mentionné sur X (Twitter). Il a écrit que c’était une excellente façon de créer du code en utilisant le langage naturel et une pleine confiance en l’IA, plutôt que la programmation manuelle traditionnelle. Après cela, il y a eu une énorme vague de hype. Et pourquoi pas ? Maintenant on peut juste parler à l’IA, et elle fera ce que les gens ont étudié à l’université et pratiqué pendant des années.
Le marketing était très puissant. Beaucoup de personnes hors IT ont commencé à construire leurs propres services web. Certains ont même licencié des programmeurs : pourquoi payer plus si on peut acheter un abonnement à 20 $ et tout faire soi-même ? Au bout d’un certain temps, on a commencé à voir les résultats : des clés API committées dans des dépôts publics, des failles de sécurité sur des sites web, des cas où des personnes dépensaient 300-400 $ en une soirée à cause d’un nombre trop élevé de tokens consommés. Dans certains cas, toute l’application cessait simplement de fonctionner.
Si vous pensez que cela n’arrive qu’à des débutants naïfs dans le métier, regardons le sujet plus en profondeur.
Vous avez peut-être entendu la nouvelle que durant l’été 2025, Deloitte s’est retrouvé impliqué dans un scandale. Il s’est avéré que leur rapport pour le gouvernement australien avait été partiellement généré par ChatGPT et incluait des lois inexistantes et des références à de fausses faits. Je l’appellerais « vibe-lawyer ». L’entreprise a subi des pertes à la fois financières et réputationnelles. Et c’est une entreprise de niveau mondial. Dans de telles entreprises, les rapports passent par de nombreux services et personnes. Mais on voit le résultat.
Un autre cas s’est produit en février 2026. Le protocole DeFi Moonwell a publié une nouvelle mise à jour. Après cela, le système a commencé à évaluer le token cbETH à environ $1.12, alors que son prix de marché réel était d’environ $2,200.
Le problème s’est avéré être une erreur de calcul de base dans la logique du smart contract. Bien que l’équipe Moonwell ait réagi rapidement et corrigé le bug en quatre minutes, le protocole a quand même subi des pertes d’environ $1.7 million.
Alors où le vibe coding entre-t-il en jeu ?
Il a été découvert par la suite que le commit introduisant la vulnérabilité avait été généré avec Claude Code. Bien sûr, il ne serait pas juste de blâmer l’IA seule. Un développeur avait reviewé le code avant le push. Mais c’est ici que le facteur humain a joué : la review n’était pas assez approfondie, et trop de confiance a été placée dans un modèle « game-changing ».
L’idée clé est simple : peu importe à quel point le code généré par LLM semble propre ou convaincant, il faut toujours penser de manière critique et considérer les edge cases.
Le vibe coding est correct si vous travaillez sur un projet personnel et voulez simplement valider une idée. Mais pour les systèmes grands et complexes, on ne peut pas compter sur le vibe coding.
Les AI Agents : une alternative aux programmeurs ?
Le deuxième mot hype après « vibe-coding » est « AI agent ». Qu’est-ce qui le différencie d’une IA ordinaire, outre le marketing ? L’autonomie. Un agent peut planifier, agir et évaluer son propre travail. Ces AI agents ont souvent accès à votre code, base de données ou autres outils de développement. Donc contrairement aux simples conversations avec ChatGPT, un agent peut planifier et accomplir des tâches plus indépendamment. Cela sonne comme une percée, n’est-ce pas ?
Peut-être que maintenant, avec de puissants AI agents autonomes basés sur les derniers modèles d’Anthropic, les programmeurs vont enfin disparaître ? Malheureusement, non.
Les AI agents ne résolvent pas le problème fondamental : ce sont toujours des modèles de langage sans véritable compréhension des objectifs et sans responsabilité pour le résultat final. Oui, ils peuvent gérer certaines tâches par eux-mêmes, en particulier le travail répétitif et routinier. Mais ils ne sont pas et ne peuvent pas être l’équivalent d’ingénieurs logiciels expérimentés.
Ce rôle appartient toujours aux humains. Seul un ingénieur expérimenté peut :
définir correctement la tâche,
évaluer les trade-offs architecturaux,
vérifier si la solution s’adapte au vrai contexte métier,
et prendre la responsabilité du produit final.
C’est pourquoi aujourd’hui l’IA n’est pas le cerveau du développement, mais ses mains. Elle accélère le processus, supprime les tâches routinières et augmente la productivité. Mais la direction, le contrôle et le sens viennent toujours d’un humain.
Où les AI agents peuvent mal tourner
Les AI agents (et les LLMs en général) viennent avec une large palette de vulnérabilités.
Un exemple récent montre à quel point ces systèmes peuvent être imprévisibles dans la vie réelle. Summer Yue, qui travaille sur l’AI safety chez Meta, a décidé d’essayer un AI agent open-source appelé OpenClaw et lui a donné accès à sa boîte mail. Elle lui a clairement dit de confirmer avant toute action.
Au lieu de cela, l’agent a commencé à supprimer ses emails par lui-même et ignorait ses demandes d’arrêter. Elle ne pouvait même pas l’arrêter depuis son téléphone et a dû courir vers son ordinateur pour le couper.
Cela montre une chose simple mais importante : même quand les instructions semblent claires, les AI agents ne les suivent pas toujours et peuvent se comporter de façon inattendue.
Au-delà de cela, vous avez peut-être entendu parler de la lethal trifecta, qui consiste en :
Accès à vos données privées : une des principales raisons pour lesquelles ces outils existent en premier lieu
Exposition à du contenu non fiable : toute situation où du texte ou des images contrôlés par un attaquant peuvent atteindre votre LLM
La capacité de communiquer vers l’extérieur : par des moyens qui pourraient être utilisés pour exfiltrer vos données
Les AI agents peuvent être vulnérables à de nombreux types d’attaques malveillantes, et le plus inquiétant est qu’ils ne le réaliseront même pas.
Et on ne parle pas seulement du cas où votre agent leak accidentellement un fichier .env dans un dépôt. Les scénarios potentiels peuvent être bien pires.
Même avec tous les problèmes mentionnés ci-dessus, les AI agents restent des outils puissants pour le développement logiciel, surtout entre les mains d’ingénieurs expérimentés. Cependant, il faut toujours rester prudent, comprendre les risques et les conséquences possibles, et s’appuyer sur sa propre expérience et son jugement.
Un monde où l’IA a remplacé les programmeurs
Imaginons une situation où l’IA moderne a effectivement remplacé les programmeurs.
Vous êtes le directeur d’une plateforme cloud à forte charge. Des centaines de clients utilisent vos services et paient beaucoup d’argent pour la stabilité et la fiabilité. Pour eux, même une minute de downtime signifie des pertes financières sérieuses, et pour votre entreprise cela signifie des pertes de réputation et financières directes.
Et puis un « beau » jour, le système cesse soudainement de fonctionner. Le monitoring est rouge, les métriques sont cassées, certains services sont indisponibles. Hier encore le code fonctionnait, les tests passaient, le déploiement était « vert ».
Vous contactez d’urgence le département IA, car il n’y a plus de programmeurs. Ils ont été remplacés avec succès par le principal AI agent responsable du développement et de la maintenance. Vous lui décrivez la situation.
L’IA répond avec confiance :
« Le problème est probablement lié à une configuration incorrecte ou à un état du système. Voici les causes possibles et des exemples de corrections… »
Elle génère plusieurs options de code, suggère de redémarrer les services, mettre à jour les dépendances, changer la configuration. Vous essayez tout, rien n’aide. Vous posez plus de questions, ajoutez du nouveau contexte, des logs, des détails d’infrastructure. Les réponses deviennent de plus en plus générales. Le contexte grandit. À un moment, les tokens s’épuisent, et le dialogue s’arrête.
Mais même si les tokens ne s’épuisaient pas, le problème principal resterait.
Il n’y a pas de véritable ownership du code.
Il n’y a pas de personne qui :
se souvient pourquoi l’architecture a été conçue de cette façon ;
connaît les accords métier cachés derrière les « fixes temporaires » ;
peut prendre une décision risquée mais nécessaire en ce moment.
L’IA ne ressent pas de responsabilité. Elle ne comprend pas qu’un système en panne coûte à l’entreprise des centaines de milliers de dollars en ce moment. Elle ne peut pas convoquer une war room, décider de tout rollback, ou rejeter une solution formellement correcte mais dangereuse. Elle continue simplement à générer des réponses statistiquement plausibles.
Le système est toujours en panne. Les clients sont mécontents. L’argent se perd.
Et puis une question simple mais inconfortable apparaît :
Qui est responsable ?
L’IA ?
L’entreprise qui a créé le modèle ?
Ou le directeur qui a décidé que « l’IA est déjà assez intelligente pour remplacer les ingénieurs » ?
Tant que l’IA ne peut pas prendre de responsabilité, posséder un système et le comprendre dans un vrai contexte métier, elle ne peut pas remplacer un programmeur.
L’avenir pour les juniors
Nous savons déjà que les LLMs ne peuvent pas remplacer les développeurs expérimentés. Mais qu’en est-il des juniors ou des personnes qui veulent démarrer une carrière dans l’IT ? Les grands licenciements dans l’IT ont commencé dès 2022, puis l’IA a ajouté plus d’incertitude. Y a-t-il des opportunités pour ceux qui commencent maintenant ?
À mon avis, la réponse est claire : oui, vous êtes nécessaires ! Il est impossible de trouver des personnes plus motivées et prêtes à apprendre de nouvelles choses que les développeurs juniors.
Je ne suis plus un programmeur débutant, mais je me souviens encore de l’excitation quand j’ai obtenu mon premier travail. Dans ma première entreprise, il y avait un principe très important appelé T-shape : vous êtes vraiment bon dans un domaine, mais vous comprenez aussi les domaines connexes. Après six mois là-bas, on m’a proposé un second projet avec un autre tech stack. Au lieu de WPF, c’était React + TypeScript. Et vous savez comment je me suis senti ? J’y ai vu une excellente opportunité d’apprendre quelque chose de nouveau. Ils m’ont donné un mois pour m’adapter, mais j’ai tout appris en 2 semaines et j’étais prêt à prendre la responsabilité d’implémenter de nouvelles fonctionnalités.
La motivation et l’amour de la programmation ne disparaissent pas quand vous devenez senior, mais les juniors restent le groupe le plus actif à cet égard.
À propos de la concurrence et de l’IA : les personnes qui comprennent leur domaine, prennent la responsabilité et continuent d’apprendre seront toujours nécessaires. Même les juniors, sans beaucoup d’expérience commerciale, ont de la valeur. Mais il faut être le meilleur parmi eux. En 2026, il ne suffit plus de simplement connaître les principes SOLID et les paradigmes OOP de base. Avec l’IA, vous devez être capable de résoudre des problèmes de niveau middle, essayer d’être indépendant et continuer à apprendre.
Peux-tu devenir le meilleur ? Si tu aimes vraiment la programmation, en es inspiré et la trouves intéressante, alors oui, bien sûr. Simplement n’arrête pas de grandir : construis tes propres projets, contribue à l’open source, étudie l’architecture des systèmes et fais preuve d’initiative. Alors aucune IA ne pourra te remplacer.
Conclusion
Les LLMs sont d’excellents outils pour le développement logiciel. Les modèles modernes augmentent vraiment la productivité et retirent beaucoup de tâches routinières aux développeurs. Mais tant qu’une véritable AGI n’existe pas, il est faux de dire que l’IA moderne peut remplacer les programmeurs. Seul un ingénieur logiciel qui comprend le domaine, connaît les processus métier et utilise efficacement les LLMs chaque jour peut « remplacer » un autre développeur.
Donc même si vous êtes un développeur senior, n’arrêtez jamais d’apprendre !
Merci d’avoir lu cet article jusqu’au bout. Je serais heureux que vous partagiez vos propres histoires d’utilisation de l’IA en développement : quels succès vous avez obtenus, où elle vous a aidé, et où elle vous a ralenti.


Discussion